
220421_플레이리스트 가져오기
서론
오늘은 오랜만에 코딩을 하는 김에 예전에 기억을 되살려서,
Crawling을 시도해보려고 한다.
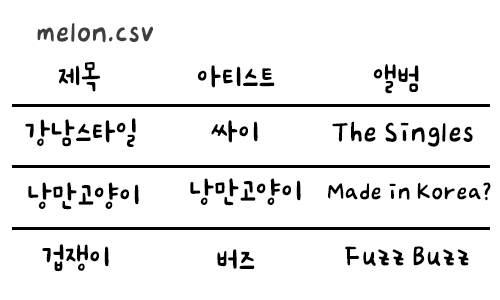
Crwaling 대상은 Melon 플레이리스트의 목록이다.
Melon을 이용했었지만 이번에 지니로 바꾸는 바람에 플레이리스트 목록을 추출해야한다.

파이썬을 사용해서 Crawling을 통해
곡명, 아티스트, 앨범 별로 분류해서 csv 파일로 저장하려고 한다.
시작해보자
페이지에 동적으로 접속해서 플레이리스트까지의 접근이 필요하다.
동적인 접근은 데이터를 추출할 페이지가 한 페이지에 한정되어 있지 않고
페이지 주소를 이동하면서 데이터를 받아와야 할 때 사용한다.
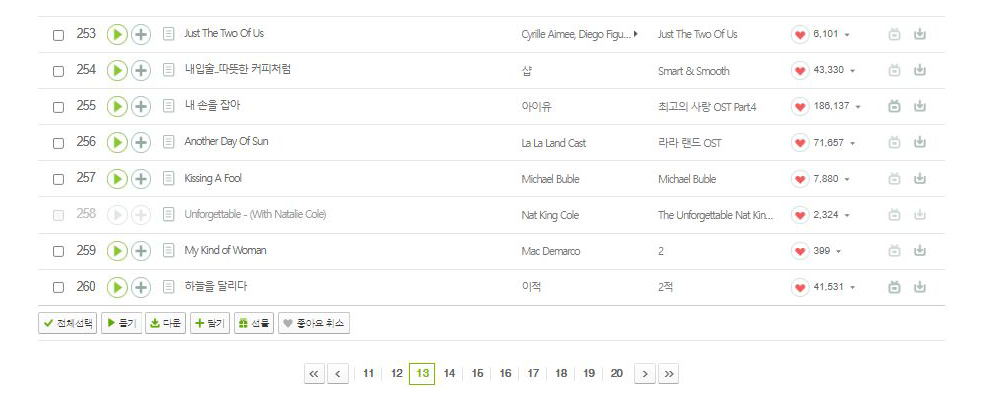
멜론 페이지를 살펴보면 페이지를 이동하면서 노래 정보를 추출해와야한다.
헷갈리는 부분은 뒤에서 살펴보자!
Selenium 라이브러리를 사용하면 동적으로 웹사이트에 접근할 수 있다.
[Selenium 다운 페이지]로 가서 버전에 맞는 Web Driver을 다운받자.
Chrome을 이용할 것이므로
[Browser 탭] - [Chrome documentation] - [Latest stable release] 를 다운하였다.

받으면 zip 파일이 다운받아 질 것이고 풀어서 나온 exe 파일을 python 프로젝트 폴더 안에 넣으면 된다.
다음으로 가상환경에 라이브러리를 설치해주자.
본인은 anaconda prompt를 사용하여 라이브러리를 설치해주었으며,
크롤링을 위해 추가적으로 설치해준 라이브러리는 다음과 같다.
pip install beautifulsoup4
코드
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait as wait
login_url = 'https://member.melon.com/muid/web/login/login_informM.htm'
wd = webdriver.Chrome('C:/드라이브에서 webdriver 설치까지의 경로 .exe로 끝나야함')
wd.get(login_url)
wd.find_element(By.NAME, 'id').send_keys('멜론 id')
wd.find_element(By.NAME, 'pwd').send_keys('멜론 password')
wd.find_element(By.ID, 'btnLogin').click()
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="gnb_menu"]/ul[2]/li/a/span[2]'))).click()
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="conts"]/div[1]/ul/li[2]/a/span'))).click()
html = wd.page_source
soup = BeautifulSoup(html, 'html.parser')
total = int(int(soup.select("#totCnt")[0].string.replace(',','')) / 20)
# 파일 읽기
f = open("C:/부터 csv를 읽어올 경로 .csv로 끝나야함", "w", encoding='UTF-8')
f.write("제목, 아티스트, 앨범\n")
for j in range(1, int(total/10)):
for i in range(1, 11):
if(i % 10 == 0):
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="pageObjNavgation"]/div/a[3]'))).click()
html = wd.page_source
soup = BeautifulSoup(html, 'html.parser')
time.sleep(2)
else:
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, f'//*[@id="pageObjNavgation"]/div/span/a[{i}]'))).click()
html = wd.page_source
soup = BeautifulSoup(html, 'html.parser')
for k in range(0, 20):
# 제목
title = soup.select("tr > td")[k * 8 + 2]
try:
filter_title = title.select('a:last-child')[0].string
except IndexError:
filter_title = title.select('.fc_lgray')[0].string
# 아티스트
artist = soup.select("tr > td")[k * 8 + 3]
try:
filtered_artist = artist.select('.fc_mgray')[0].string
if (int(len(artist.select('.fc_mgray'))/2) > 1):
for l in range(1, int(len(artist.select('.fc_mgray'))/2)):
filtered_artist = filtered_artist + ',' + artist.select('.fc_mgray')[l].string
except IndexError:
filtered_artist = artist.select('.checkEllipsis')[0].string
# 앨범
album = soup.select("tr > td")[k * 8 + 4]
filtered_album = album.select('.fc_mgray')[0].string
f.write(filter_title + "," + filtered_artist + "," + filtered_album + "\n")
# print(filter_title, filtered_artist, filtered_album)
time.sleep(2)
f.close()
#웹창을 바로 shut하지 않기 위해 선언
while(True):
pass
크게 사용한 것은 selenium을 통하여 webDriver을 사용한 것과
BeautifulSoup를 통하여 데이터를 추출한 것이다.
아이디, 비밀번호 입력 후 로그인
login_url = 'https://member.melon.com/muid/web/login/login_informM.htm'
wd = webdriver.Chrome('C:/드라이브에서 webdriver 설치까지의 경로 .exe로 끝나야함')
wd.get(login_url)
wd.find_element(By.NAME, 'id').send_keys('멜론 id')
wd.find_element(By.NAME, 'pwd').send_keys('멜론 password')
wd.find_element(By.ID, 'btnLogin').click()
Chrome 창에서 아이디와 비밀번호가 입력되고 로그인이 실행된다.
Xpath를 사용해서 버튼 클릭
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="gnb_menu"]/ul[2]/li/a/span[2]'))).click()
wait(wd, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="conts"]/div[1]/ul/li[2]/a/span'))).click()
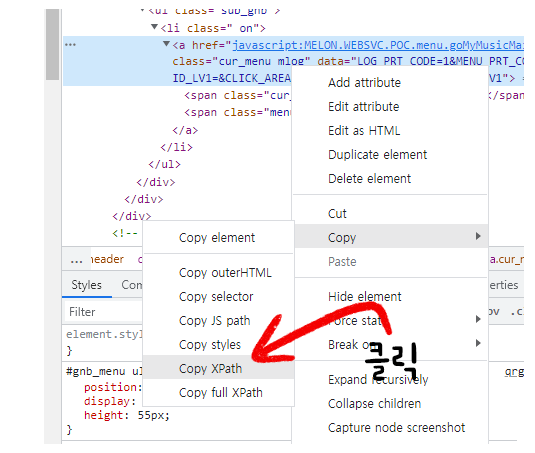
원하는 객체의 Xpath 경로를 통해 버튼을 클릭해서 페이지까지 동적으로 접근한다.
Xpath 경로를 찾는 방법은 개발자 도구인 [f12]를 클릭한 뒤 버튼 또는 링크의 객체를 찾은 뒤
태그 부분에서 오른쪽 마우스를 누른다음 [Copy] - [Copy XPath]를 클릭하면 된다.
그 이후 코드로는 Beautifulsoup를 통해서 플레이리스트 페이지를 넘겨가면서 데이터를 추출하는 과정이다.
Beautifulsoup를 사용하면 HTML 페이지에서 데이터를 쉽게 추출해 올 수 있다.
마무리
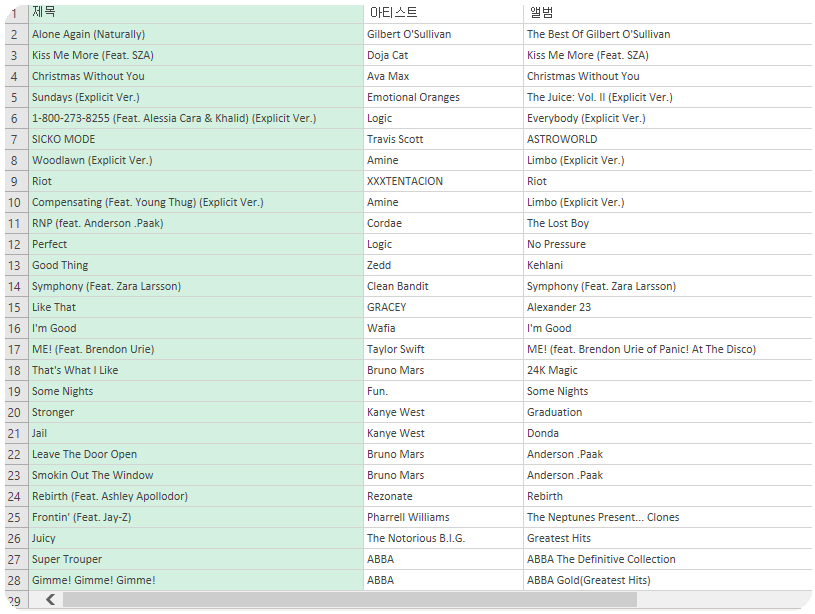
csv를 저장하는데 위의 코드대로만 진행한다면 한글이 깨질 것이다.
이는 [행궁동 데이터엔지니어: 엑셀로 .csv 파일 열 때 한글이 깨져요에 자세히 나와있다.
excel 파일을 하나 열고 csv 불러오기를 할때 utf-8형식으로 불러오면 한글이 깨지지 않고 잘 불러와지는 것을 볼 수 있다.
댓글남기기